Programming#
The real power of computers, of course, comes from programming them. Knowing how to
program even a little bit unlocks untold opportunities to make the computer work better
for you in the most personal of ways. Besides, programming skills also unlock very
well-paying jobs. The advent of Machine Learning-assisted programming is clearly going to
make an impact on the art of programming in general, but in order to be ML/AI-assisted,
you’ll want to have a solid foundation in the basics regardless. In this chapter, you’ll
try a version control system called git, write a few simple Python programs, find
resources on machine learning, and be introduced to a web app framework called Django.
Tracking changes of anything#
Even if you never program, you will benefit from knowing about version control systems (VCS). A VCS allows you to create a rewindable timeline of anything you’re working on. Think of it like the “Track Changes” feature of a word processor, but more powerful and for more than just documents.
VCSs are generally associated with programmers because they really benefit from having a rewindable timeline of their software. This comes in handy often, such as when a program that used to work no longer works. Programmers look at the timeline of the source code changes, rewind it, and play it back, all the while running their program to find out where the bug was introduced.
Some people keep their résumé in a VCS. They want to see it progress, and also “branch” it to make slightly different versions for various job applications.
A VCS is also wonderful for collaboration. You know how people e-mail around versions of
documents like Proposal_FINAL_final_nt_jrc2_draft.docx? A VCS can make that kind of
operation much better. Everyone can work on their own copy of a document and then these
can be merged together. One hiccup with this approach is that VCS works best with pure
text files so if you want to go this route, consider a lightweight markup language like
ReST or Markdown (see Publishing).
Some notable VCSs include git, mercurial, subversion, and Perforce. Git is a fairly universal favorite. It’s the eponym of the famous GitHub, which Microsoft acquired in 2018 for several billion dollars.
Using git#
Git has a slight reputation of being hard to learn. Fear not, it’s not that bad. Git is made for the command line, but can be used graphically if you prefer. For the most common uses, you only need to know a few commands. Here they are:
Command |
Purpose |
|---|---|
|
Initialize a new |
|
Make a local copy of a remote repository (e.g. from GitHub or your team) |
|
Mark one or more files to be part of a new commit that is in process |
|
Take all marked changes and package them as a discrete “change” to be remembered forever. |
|
Update the local repository with any changes someone else made on the remote server. |
|
Send all our local commits to the remote server (for collaboration) |
|
View all changes you or anyone else has made |
|
Check out a previous commit or separate branch (for going back in time or trying alternate paths) |
The best way to learn is to try it out and experiment.
OS |
Command |
|---|---|
Windows |
|
Linux |
|
macOS |
|
In a new empty folder, run git init to start a new repository. Create a new text file called
file1.txt in the folder using your text editor and write a few lines in of your choosing. For
example:
Uncle Dave: Married to Rose; likes putt-putt
Aunt Malia: Went to University of Michigan
Cousin Jingjing: From Hawai'i
Third-cousin Pete: Enjoys cooking
Stage it with:
git add file1.txt
Commit it with:
git commit -m "Initial commit of relatives"
Make some changes to the file. Delete a line or add a new one. View the differences from the last commit by running:
git diff
Stage and commit the new changes (by repeating the steps above). Now let’s say you want to go back to the initial version of the file by rewinding it to the first commit. First, you need to find out what the commit’s “address” is, which is a long string of letters and numbers. Run:
git log
to get a list of commits. Copy the first 8 or so letters/numbers from the first commit’s address and fill them in for your version of the following command (your address will be different):
git checkout a3e2b54
Now look at the file and you’ll see that it’s at its original commit. Go back to the latest commit with:
git checkout master
There, you’ve used most of the primary git operations now. Undoubtedly some of these
commands will feel a bit mysterious still. There’s a whole free book on it on the
official git web page called Pro Git and countless tutorials on the internet. We’ll do
a similar example but on a collaborative repository in the next section.
Besides working on text files, there is also an extension called Git Large File Storage (LFS) that can be used to store big binary assets efficiently in a git repository (graphics design files, science files, etc.). Git-annex, as alluded to in Backups, can track information about large sets of files without storing the files themselves in the git repository. This was originally built for managing metadata and synchronization of photo and music libraries. It’s finding uses in advanced areas like big-data research as well.
Fixing something in a GitHub repository#
GitHub is a website (now owned by Microsoft) that stores thousands of projects’ git repositories. You can clone, pull from, and push to it to collaborate on building software. As an exercise let’s see if we can contribute to an open-source project.
First, you’ll need a GitHub account (use your password manager to make your password!). Next, find a repository to send a pull request too. You can either make your own repository and use it, or actually make a contribution to another team’s. One really easy one to try would be to search GitHub for common misspellings of a word and then just make a change to correct it. It’s best to find misspellings in comments so you don’t risk messing up the code. Even better, add some clarification to the documentation of a project you’ve been using a little.
Note
Make sure the repository has recent activity or else the maintainer may not ever respond to your pull request.
Operation |
Description |
|---|---|
Fork the target repository |
Choose a repository to update and navigate to it. Click the “Fork” button in the GitHub web page. This will make a copy of the repository on your own account. |
Clone your copy of the repository to your machine |
From the command line, run |
Make the modifications to the source code on your computer |
Navigate to the file(s) you want to change, change it, and save it. |
Stage and commit your changes to your local repository |
Run |
Push the changes up to your personal fork of the repository on GitHub |
Run |
Create a pull request to communicate with the original team |
There should be a button on your GitHub now that says “Pull Request”. Click it and fill in the form with details of what you changed and why. This will now enter into a review/approval process with the original team. If they accept it, your change will go live. |
That’s it. As usual, this is just scratching the surface, but these are the fundamentals. If you can do this, you are basically ready to participate in collaborative development or publishing using git. And with that, let’s get to the actual programming.
Why program?#
Programming is the Holy Grail of digital superpowers. Things like Machine Learning, gaming, business process, social networking, and so on are rooted in programming. Of course, it is an entire discipline that can take years or even decades to truly master, but you can do meaningful things very readily, and go from there as suits your situation. If you want, you can make an entire well-paid career out of it. Or you can just dink around.
I’m fairly convinced that programming should be a fundamental topic in middle schools all the way up, possibly even displacing some required math curriculum that very few people end up using. I say this as a Ph.D. hard-science engineer: I have never ever had to do long division of polynomials and I never will. But boy have I seen people in all walks of life struggle with things where a bit of programming exposure would have helped.
The single best way to learn how to program is to recognize that you have a problem you want to be solved, and that a program could help you solve it. For example, a friend of mine who is now an applied mathematics professor at Harvard gave me his favorite math riddle once:
Given two 8’s and two 3’s, combine them with the four basic math operations (+, −, ÷, ×) to get 24. You have to use each. For example, 8+8+3+3 is a valid guess, but it’s wrong because that equals 22, not 24. Similarly, 8×3=24 is invalid because you only used one 8 and one 3.
I struggled for a while and decided that a program guessing all the potential options would be useful. In the end, it worked!
More practically, a friend was doing some medical research using a large dataset of pharmacy refill data and was going through this painstaking and error-prone process in a spreadsheet to quantify potential medication gaps. She explained her process in detail and then I helped her whip up a little program that did what she was doing. Thus, she was liberated to tweak and debug her process. She ran the program dozens of times, analyzing the algorithm she was using and coming up with interesting conclusions.
Personally, I’ve spent many years writing programs that help simulate nuclear reactors. Once we have a virtual nuclear reactor we can adjust its design and perform “experiments” that would cost billions of dollars to run in the real world until we think our design is optimal. We have to put a lot of effort into making sure the models match reality (e.g. by simulating things that really operated and comparing results to measurements). The synergy between physical models, numerical simulations, and experiments is a real work-horse in science and engineering across the board.
Then, of course, professional programmers build and maintain all the massive software systems behind a large fraction of our everyday experiences.
Programming languages#
Hundreds of programming languages exist. Each of them has the goal of translating (or compiling) human input (source code) into electrical operations the computer can perform. Their differences arise from different trade-offs their creators were aiming for:
Is it better to have a really fast-running program that can crash without saying why, or one that runs slowly but tells you in detail where it was when something went wrong to help with debugging?
Should the same source code run on many types of computers, or should the programmer have to maintain different versions for different machines?
Should the programmer have to wait 10 minutes between changing the source code and running the program so the compiler can optimize aggressively, or should it be instantaneous?
Very low-level programming languages like assembly run extremely quickly, but require customizations for every model of CPU and are challenging to write. Conversely, high-level languages like JavaScript are pleasant to read but generally slow. One of the more recent and very popular languages, Rust, attempts to let programmers write very “safe” code (if it compiles it will have fewer bugs than usual) while still running extremely quickly, and in parallel.
Among the data science, automation, web, and engineering industries (and many others!), the Python language has been doing very well in the past decade or two. It’s a high-level interpreted language that runs slowly on its own. But it’s so popular that people have interfaced it nicely with some lower-level screaming-fast math, graphics, and machine learning libraries, rendering it a pretty good workhorse. There’s also a vibrant collection of other modules people have made that do all sorts of things like statistical analysis, graph creation, and web apps. Here, we’re going to try out Python. Depending on your end goal, another language may be better.
Writing Python programs#
Before writing a Python program, we need to download the Python interpreter. It’s what translates Python code into actual operations your computer can perform.
Note
You can skip this step
if you already have Python installed. Find out by running python -V in your
command line and seeing if it throws an error.
OS |
Command |
|---|---|
Windows |
|
Linux |
It’s almost definitely already installed |
macOS |
It’s almost definitely already installed |
Run python -V to make sure it works. If you just execute python at the command
line, you’ll be presented with a Python prompt that looks like >>>. Typing exit()
will exit out when you’re done. You can type
Python commands here, and they will execute one after the other. For example, we can use
it as a calculator. First just with numbers:
>>> 2+2
4
All programming languages have variables where you can store the result of some
operation in a name like x or number_of_customers:
>>> x=2
>>> y=5
>>> x+y
7
You can also define sequences and then repeat an operation on all elements in the sequence in a loop:
>>> names = ["Ford", "Honda", "Jeep", "Chevy"]
>>> for name in names:
print(name.upper())
FORD
HONDA
JEEP
CHEVY
Built-in libraries provide the ability to do useful things like sample random numbers. When you run these, you will see different numbers.
>>> import random
>>> random.random()
0.8254737295983463
>>> random.random()
0.2630839054490208
>>> random.randint(1,100)
88
>>> random.choice(['Pizza','Ramen','Eggs','Pho'])
'Eggs'
Random numbers are fundamental to things like games and cryptography. That last line is basically a universal 8-ball, which is useful if you need help deciding what’s for dinner.
Note
At this point, you’re well poised to run through the official Python tutorial. It mostly targets people who have programmed a little before, but even if you haven’t, it’s easy to follow along and get some exposure to the syntax and possibilities.
Running commands line-by-line in the Python prompt is useful for exploring and simple tasks, but real programs are written as sets of commands in text files. See Text editors and extensions to make sure you have an appropriate program for creating source code.
A program to approximate \(\pi\)#
Let’s make a real program that does something neat: approximates \(\pi\) with the Monte Carlo method. This leverages the fact that computers cannot get bored to approximate a fundamental constant of nature basically by throwing darts.
Imagine you are blindfolded and throwing darts at a perfectly square board with a side length of 1 m and with a circle drawn on it that just touches the edges. If you throw randomly, the number of darts that land inside the circle will be proportional to the area of the circle, while the number of darts that land anywhere on the board will be proportional to the area of the square. If you throw millions upon millions of darts, these approximations will become pretty good, and your counts will tell you what \(\pi\) is.
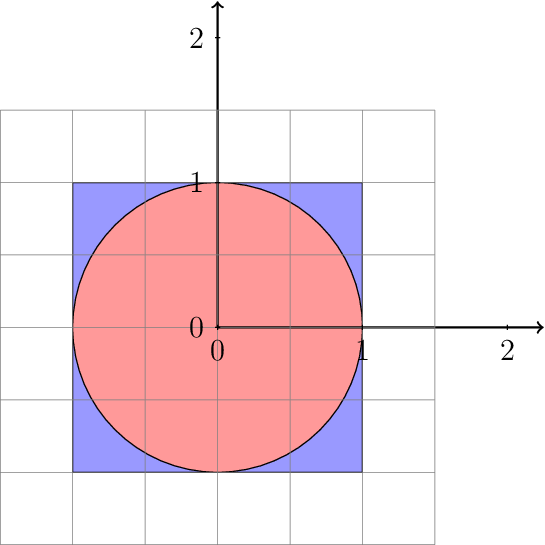
The dartboard
Dividing those equations gives:
Instead of throwing the darts ourselves, we can write a program to simulate the dart tosses and
approximate the area ratio. To do so, we put the following in a new text file called darts.py.
Note that all lines beginning with # are just comments and are not executed (so you
don’t have to type them).
import random
RADIUS = 1.0 # define a constant
num_in_circle = 0 # initialize our count
# ask user how many darts to toss
num_darts = int(input('Number of darts: '))
for _individual_dart in range(num_darts):
# for each dart toss, grab two random
# numbers between 0 and 1.
x = random.random()
y = random.random()
# Anyone remember the distance formula?
# We can skip sqrt here because sqrt(1) = 1
d = x**2 + y**2
if d < RADIUS:
# increment count in circle
num_in_circle = num_in_circle + 1
pi = 4*num_in_circle/float(num_darts)
print('Pi is approximately: {}'.format(pi))
Run the program with $ python darts.py at the normal command prompt, not the Python one. If
you still see >>> at your command line, run exit(). It should give:
$ python darts.py
Enter the number of darts: 100000
Pi is approximately: 3.14504
Pretty close! The correct answer is 3.1415926.... If you only run a few
darts, the answer will be much more wrong (try it!). Ah, the central limit theorem in action!
My computer only takes a second to do 1 million dart tosses, but don’t do too many, it may take too long! Remember: Ctrl-C will abort a running program if you get stuck.
The program only samples numbers between 0 and 1, so we’re really only operating in the first quadrant of the dartboard (top left). This is OK because the dartboard is symmetrical.
What if we want to plot our results? We’ll need some third-party libraries to do that
(things that are part of the Python community but not included in Python itself). To get
them, use the Python package manager, which is called pip. It’s very similar to the
system package managers we’ve been using, but it just pulls in Python modules. We need two
things to have plotting:
pip install --user numpy
pip install --user matplotlib
We have to modify the program to keep track of the (x, y) coordinates and then plot
them in the end. So we’ll make lists to store each coordinate. Here goes (this time as
darts_plot.py):
import random
import matplotlib.pyplot as plt
RADIUS = 1.0
coords_inside = []
coords_outside = []
num_darts = int(input('Number of darts: '))
if num_darts > 1000000:
# error checking
raise RuntimeError('Too many particles.')
for _individual_dart in range(num_darts):
x = random.random()
y = random.random()
d = x**2 + y**2
if d < RADIUS:
# add to the list of coords inside circle
coords_inside.append((x,y))
else:
# also track outsiders for plotting
coords_outside.append((x,y))
pi = 4*len(coords_inside)/float(num_darts)
print('Pi is approximately: {}'.format(pi))
# Make plot
# unpack x's and y's into their own lists
xinside, yinside = zip(*coords_inside)
plt.plot(xinside, yinside, 'b.',label='Inside')
xoutside, youtside = zip(*coords_outside)
plt.plot(xoutside, youtside, 'gx',label='Outside')
plt.grid()
plt.legend()
plt.title('Approximation of $\pi$')
plt.xlabel('x (m)')
plt.xlabel('y (m)')
plt.show()
# uncomment to save as file
#plt.savefig('darts.png', dpi=200)
Warning
For this version, you better not try running too many darts or else your machine really might crash.
And here is the result:
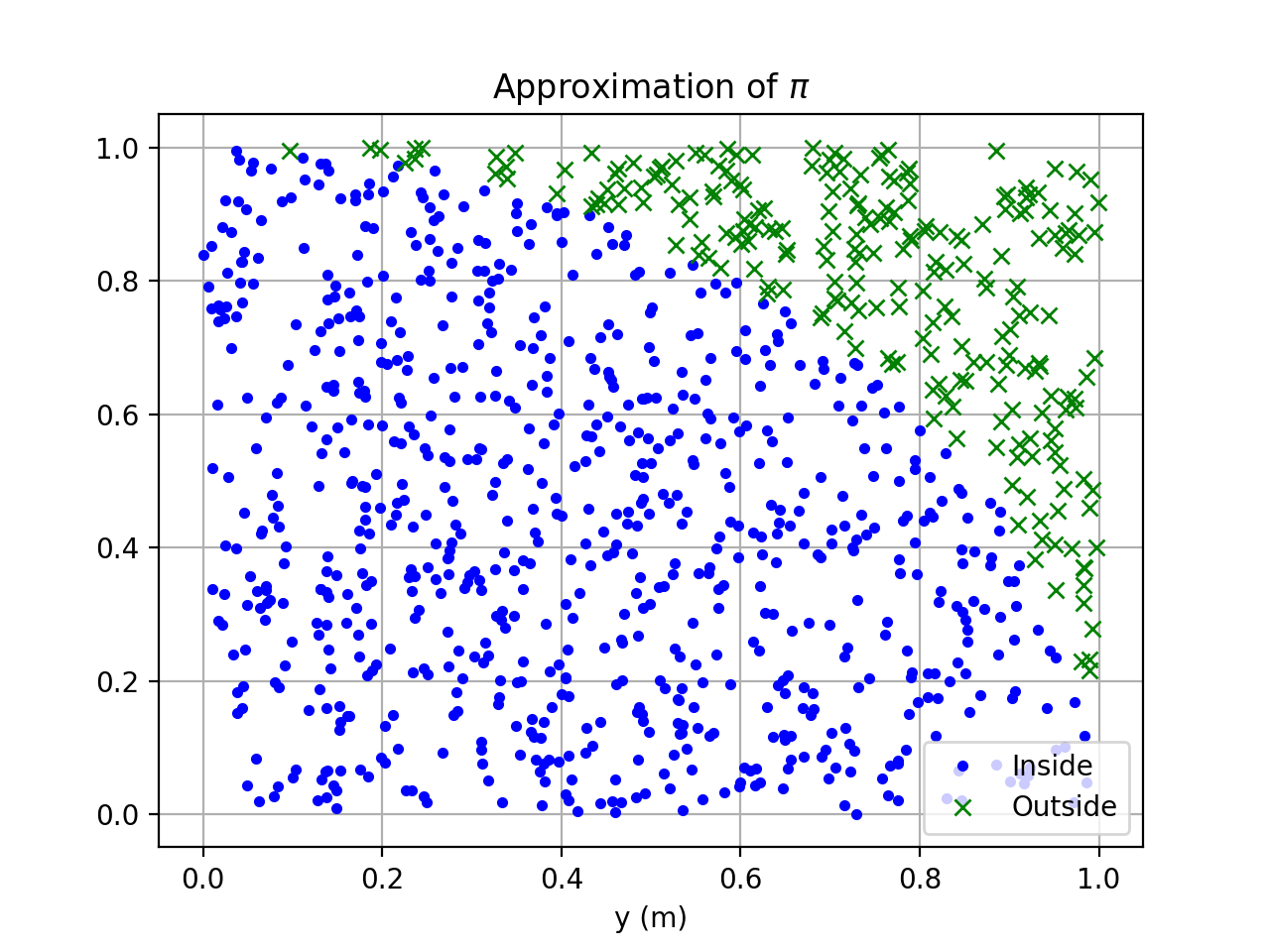
Plot of 10,000 darts hitting or missing.#
Pretty fancy! This is admittedly a very inefficient method to approximate \(\pi\). The fundamental method of generating random numbers and running computerized trials, however, is extremely powerful and valuable. First used to model thermonuclear weapons on the original mainframes in the 1950s, these methods are used all over science, engineering, risk management, insurance, and finance. Now you’re well on your way to becoming a high-powered quant mega-millionaire on Wall Street.
For more inspiration about what kind of plots you can make with Python (as well as example code to learn how to do it), check out the matplotlib gallery and plotly.
A linear regression#
Python is great for stats. This is often useful for your research teams and around the house (I once used regressions to estimate what time the furnace had to turn itself on to get up to the desired temperature given the outdoor temperature each morning during the Michigan winter). Let’s do a simple example of reading data in directly from Excel. The pandas library provides high-level data analysis capabilities, but we’re just going to use it for reading from Excel:
pip install --user pandas
pip install --user xlrd
We need some data to process. Open up your favorite spreadsheet program (Excel or Open Office Calc will work fine, for instance) and let’s generate some noisy data. Let’s use a line from this formula:
where:
Note
If you have your own data you want to do a regression on, just load that up instead!
In a new spreadsheet, label the first two columns X and Y. In the first column,
enter the formula: =RAND()*5 to get random x-values between 0 and 5. Click the little
black box in the bottom right corner of the cell and drag it down 30 or more cells to get
lots of random X values. Then in the Y column enter our line as =3.5*A1 + 2.3 +
(RAND()*8-4) [3]. Double-click its little black box to fill down. Save the file as
data.xlsx. It will look like this:
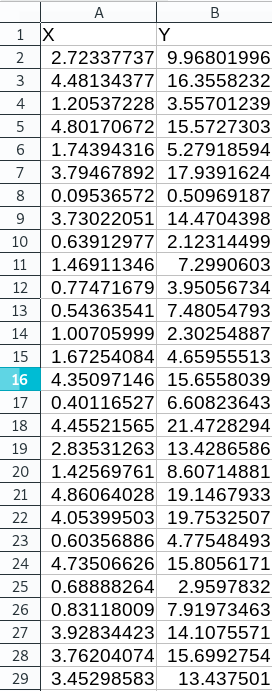
Example noisy data simulating our line. Yes we could use Python to make these data but many of us receive data in spreadsheets.#
To do the regression:
from scipy import stats
import pandas
# Read data
data = pandas.read_excel('data.xlsx')
# Grab the columns we want
x = data['X'].values
y = data['Y'].values
# Compute the regression
results = stats.linregress(x,y)
# unpack results into useful names
(slope, intercept, r_val, p_val, std_err) = results
# Display results
print('Slope: {}'.format(slope))
print('Intercept: {}'.format(intercept))
print('R-squared: {}'.format(r_val**2))
print('P-val: {}'.format(p_val))
Here’s the result with my data:
Slope: 3.473511906229649
Intercept: 1.8192562724560553
R-squared: 0.861400909580644
P-val: 1.1563714298035524e-12
That’s all it takes to do a regression! We can plot it too, by adding this code:
# Make a plot while we're at it.
import matplotlib.pyplot as plt
import numpy
modelX = numpy.linspace(0,5,10)
modelY = modelX * slope + intercept
fig = plt.figure(dpi=300)
plt.plot(x,y,'o', label='Data')
plt.plot(modelX, modelY, '--',label='Model')
# Add labels & formatting fluff
plt.title('Beautiful regression')
plt.xlabel('X')
plt.ylabel('Y')
plt.grid(linestyle='--')
plt.legend()
plt.text(3.1,3.0,'m={:.3f}'.format(slope))
plt.text(3.1,2.0,'b={:.3f}'.format(intercept))
plt.savefig('regression.png')
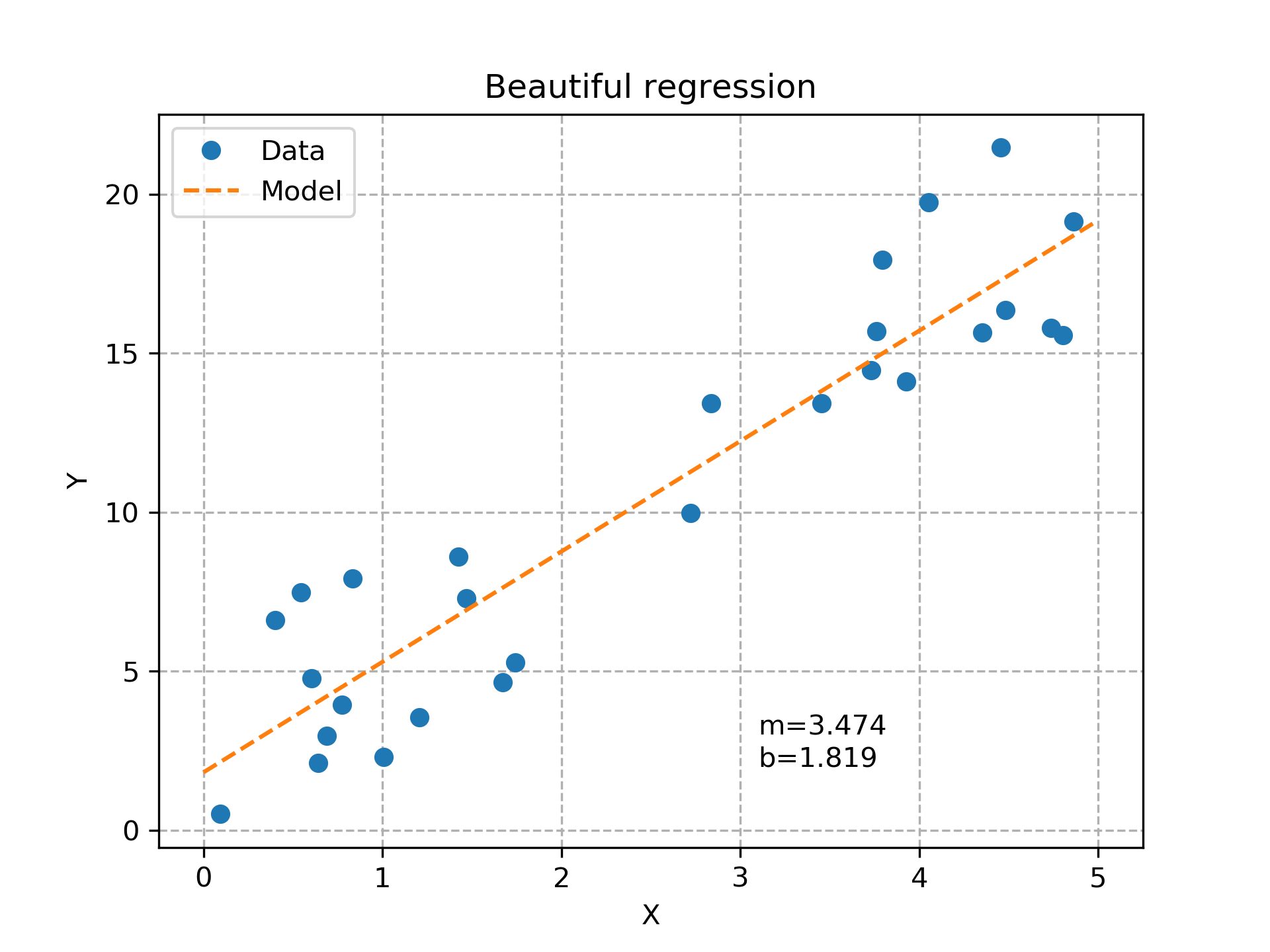
The random data plotted with the best linear fit.#
Hey, not bad! Note that by defining the plot in code, we can afford to spend time polishing its look to be very professional because we only have to do that part once. We can then throw a billion different data sets at this program and not have to spend a second plotting the results; we already did it once, the computer’s got it from here.
Exercise
Make the noise go from -1 to 1 and see if your \(r^2\) value gets closer to 1.0!
Note
Another great tool for data processing is called R. There’s plenty of debate about
whether Python’s better than it. It’s fair to say that Python is sufficiently good at stats for
production research and has the advantage of being very general-purpose, so if you learn it, you
get stats plus anything else it can do, whereas R is more specialized for stats only.
The bridge to machine learning#
From self-driving cars to face recognition to the Terminator, machine learning (ML) is quite a hot topic. The reason it’s gotten so good is that computer graphics cards have gotten extremely fast at doing matrix-vector multiplication, largely driven by the gaming industry (where this math is required for shading as players move around). Combine this with the universal function (capable of mapping any arbitrarily-complex input to an arbitrarily-complex output) that is the Convolutional Neural Network and massive datasets to train them on (e.g. vast quantities of selfies) and you’ve got yourself a machine learning revolution.
One good way to get your hands dirty in ML is to dedicate yourself to some fast.ai courses. These free online courses are cutting-edge, and require roughly 8-hours per week for two months or so. Not everyone’s computer is going to be good at training on large datasets (unless you’re a gamer), but you can try it out (I got my computer working on them). Better yet, they set up a cloud environment at Amazon Web Services where you can just log into computers “in the cloud” that are more than capable of doing the exercises in the class.
Note
Much ML work is done through Python, which interacts with heavier-weight libraries under the hood. That’s another good reason to choose Python as a first programming language.
A simpler introduction to computer vision (sort of related to ML) is to play around with the OpenCV library. It has good Python bindings and you can even get it going on a $35 Raspberry Pi mini-computer. I’ve seen people make license plate readers, recognize family members’ faces, analyze video of experiments to collect data, and lots of other useful things.
A trivial (non-ML) example usage of it is to get some data out of a movie file. I had a high-speed video of a light mill and wanted to see how fast it was spinning by analyzing the video [2]. OpenCV is perfect for this. I figured out which pixel I wanted to watch and then extracted intensity vs. time with a simple program:
Figuring out which pixel to read.#
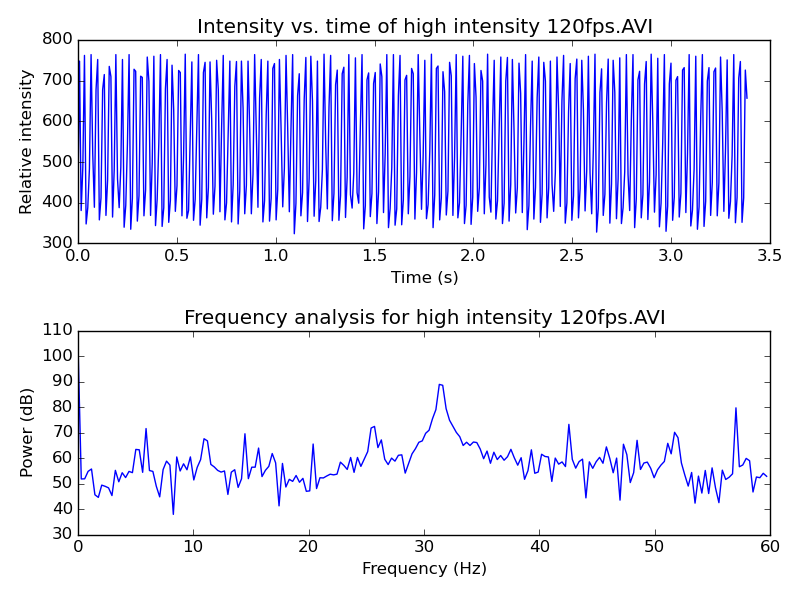
Plotting and analyzing the intensity data. Looks like it’s spinning at about 32 vanes per second. These devices, actually called Crookes radiometers, were originally scientific equipment that could be combined with a stroboscope to measure the intensity of light.#
The (partial) code for reading this looks like this:
import cv2 # bring in the OpenCV library
def measureIntensities(videoFileName, pointOfInterest):
"""Find the intensity of a point of interest in each frame"""
video = cv2.VideoCapture(videoFileName)
intensities = []
while video.isOpened():
_returnCode, frame = video.read()
if frame is None:
break
pixelValues = frame[pointOfInterest]
intensities.append(pixelValues.sum())
video.release()
return intensities
If you have video of something and want to quantify some element of it with a computer, OpenCV is your ticket. Once you are comfortable with simple things like this, you can try out facial recognition and license-plate reading with it as well.
Graphical User Interfaces#
Making desktop applications GUI with dialogs, buttons, menus, and forms can make your programs more accessible and user-friendly. Most programming languages enjoy GUI frameworks that do most of the hard work of making such interfaces. In Python, we have Kivy, wxPython, PyQt, Tkinter, and dozens of others. I picked up wxPython first because of its excellent demo app that lets you try out all its hundreds of widgets interactively with sample code. Kivy is nice in that it can even run on cell phones. PyQt is especially polished, though it requires a commercial license if used in commercial software (not that there’s anything wrong with that).
Perhaps the most universal and modern GUI system is a web browser, which brings us to the next topic.
Web applications#
Almost every web page you go to these days is actually a web application, meaning it’s running some program behind the scenes and presenting the results to you through a web browser like Firefox or Chrome. Almost always, there’s a database sitting on the back end containing the information. For instance, Facebook is conceptually a web-based view of user data stored in a database and governed by rules and process.
The possibilities with web apps are nearly endless. Unfathomable yet-to-be-created businesses and services will be web apps. A home inventory could be a web app. Twitter is a web app. Reddit is a web app. The programs driving web apps are written in many varieties of programming languages, just like offline applications. Through the years, though, various frameworks have evolved that contain commonly-needed pieces of web applications, like user authentication, secure form submission, and secure database access. Starting with a web framework is a great way to become productive at making safe and performant web apps rapidly. The hundreds of web frameworks out there all have distinct pros and cons. We will highlight only one of them here.
Instagram and the Washington Post are among the thousands of web apps built upon a web framework called Django (“The D is silent”). Django is surprisingly nice to use. Having come from a Python background, the fact that it uses Python made it extra easy for me to pick up. I went through their Writing your first Django app tutorial and was off and running. This was really an exciting moment for me because I could just feel my mind expanding… “So many new possibilities. I can make any web app out there with this thing!” It’s the closest thing to leveling-up I think I’ll ever experience.
Django is extremely well documented and has a fun, engaged community. For example, Django Girls is a non-profit centered on teaching Django to girls around the world while building interest in programming.
Note
One mental model that’s often used in these kinds of applications is the “Model-Viewer-Controller” (MVC) pattern. The model is the database organized somehow, the viewer is the web page rendered with the data in it, and the controller is the code running to figure out what to show when, and what you are and are not allowed to do. By separating these units out, the code remains easy to maintain. Django is designed around MVC.
The sheer magnitude of capabilities Django and its add-ons bring is impressive. Once you get to the point where you’re defining models, a lot of impressive systems activate automatically. For example, let’s say you were making a discussion forum where you had made some models that look like this:
class Post(models.Model):
title = models.CharField(max_length=300)
poster = models.ForeignKey(User)
posted = models.DateTimeField()
votes = models.IntField(default=0)
class Comment(models.Model):
title = models.CharField(max_length=300)
poster = models.ForeignKey(User)
post = models.ForeignKey(Post)
posted = models.DateTimeField()
votes = models.IntField(default=0)
The automatic administration panel would allow you to populate the database with information.
It presents you with web-based widgets that are appropriate for each data type. The
DateTimeField has a calendar pop-up picker and the ForeignKeys have
drop-downs with links to the other instances. You can build custom forms for your users
that automatically get these widgets as well. You can also use the Django REST
framework (an add-on) which will set up an entire system to interact with this app from
other places (other web apps, desktop programs, phones, etc.). In other words, all the
things you typically need to be done with a web app have built-in or readily available solutions.
I simply cannot emphasize how empowering this is. If you learn it, you’ll start wanting to automate all sorts of inefficiencies around your office, research team, warehouse, or wherever you find them. The official documentation cannot be improved upon and so to get started, simply head on over to it and begin. Having Python installed from the previous section is all you need to get going. I look forward to hearing about the wonderful things you do with these systems.
Note
Sysadmin skills in running a web server are useful for setting up production-caliber Django apps, though you can start building apps right away using the built-in test server that comes with Django.
And there you have it, the ultimate computer superpower. The skills you’ve started here can change the world, or simply make your life a little better. I hope you’ll find some exciting, interesting, and helpful uses of these technologies.
Footnotes